In the dynamic world of software testing, flaky tests are like unwelcome ghosts in the machine—appearing and disappearing unpredictably and undermining the reliability of your testing suite.
Flaky tests are inconsistent—passing at times and failing at others—without changing the code or the test environment. This inconsistency makes them unreliable as indicators of software quality and stability.
The problematic nature of flaky tests stems from their unpredictability, which introduces several challenges in software development and testing processes:
- Erodes trust in testing suites: When tests do not consistently reflect the state of the code, developers and testers may question the validity of all test outcomes, not just the flaky ones. This skepticism undermines the core purpose of test automation as a reliable method for ensuring software quality.
- Wastes time and resources: Flaky tests frequently demand manual intervention to distinguish genuine code issues from mere test flakiness. This troubleshooting consumes a valuable amount of time and diverts resources from productive development endeavors.
- Obstructs continuous integration (CI) and continuous deployment (CD): In CI/CD environments, automated tests play a crucial role in assessing build stability for progression to the next stage. Flaky tests can lead to unnecessary build failures, causing delays and complications in deployment.
- Masks real issues: If flaky tests frequently fail for no substantial reason, there’s a risk that their failures might be dismissed as “just another flake,” potentially overlooking genuine defects in the software. This complacency can lead to bugs being deployed into production.
- Complicates test maintenance: Flaky tests complicate test suite maintenance by making it challenging to distinguish between a new bug and flakiness-related failures. This complexity results in bloated and inefficient test suites during updates and maintenance.
- Reduces development velocity: Managing flaky tests significantly slows down the development process, as teams often need to rerun tests to confirm genuine failures. This causes delays in feature development and the debugging process.
Flaky tests are problematic because they compromise the efficiency, reliability, and effectiveness of automated testing. This can lead to increased development costs and potentially affect the quality of the end product.
How to identify flaky tests

Identifying flaky tests begins with monitoring and tracking your test suite’s reliability over time. Tools and techniques such as rerunning failed tests automatically, employing specialized software to analyze test patterns, and maintaining detailed logs can help pinpoint erratic tests. Recognizing these tests early on is critical to maintaining the health of your CI/CD pipeline.
Here’s how to identify flaky tests, recognize their common signs, understand their causes, and analyze test failures effectively.
Repeat test execution
One straightforward method is to repeatedly run the same set of tests under the same conditions to see if the outcomes vary. Tests that sometimes fail and sometimes pass without any changes in the code or environment are likely flaky.
Use specialized tools
Implement tools and plugins to detect flaky tests. Many continuous integration systems and test frameworks offer features or extensions to help identify flaky tests by automatically rerunning and tracking their pass/fail status over time.
Test history analysis
Review the historical data of test executions. Tests that show a pattern of intermittent failures across different builds or environments may be flagged as flaky.
Common signs of flaky tests
Understanding and addressing the signs of flaky tests are essential for maintaining a robust testing infrastructure, improving development workflows, and ensuring the accuracy and efficiency of automated testing practices.
| Sign of Flakiness | Description |
| Inconsistent results across runs | The test alternates between passing and failing across multiple test runs without any code changes. |
| Dependency on external systems | Tests relying on external services, databases, or networks may exhibit intermittent failures, indicating flakiness due to external dependencies. |
| Sensitivity to timing or order | Tests that fail only under specific timing conditions or when executed in a certain order, such as faster or slower execution times, often suggest flakiness. |
Common causes of tests becoming flaky
Knowing the causes of tests becoming flaky is essential for maintaining the effectiveness and credibility of automated testing processes. It enables teams to proactively address issues, optimize resource usage, and build a robust testing infrastructure that supports efficient and reliable software development practices.
| Causes of Tests Becoming Flaky | Description |
| Concurrency Issues | Tests running in parallel that interfere with each other can lead to unpredictable outcomes. |
| External Dependencies | Reliance on third-party services, APIs, or databases that may not always behave consistently or are subject to network variability. |
| Timing and Synchronization Problems | Tests that fail or pass depending on how quickly certain operations are completed, often due to inadequate wait conditions or assumptions about execution time. |
| Non-deterministic Behavior | Using random test data or relying on system states that may change between test runs can introduce variability in test outcomes. |
| Test Environment Instability | Differences or changes in the test environment, such as software versions, configuration, or available resources, can cause tests to behave flakily. |
How to analyze test failures to determine flakiness

By systematically identifying flaky tests, understanding their signs and causes, and thoroughly analyzing failures, teams can address the root causes of flakiness and improve the reliability of their testing efforts.
Key steps in analyzing test failures to determine flakiness include:
- Isolate the test: Run the test in isolation several times to see if it consistently produces the same result. This helps determine if the test’s failure is due to its flakiness or the influence of other tests.
- Review logs and outputs: Examine the test logs, error messages, and system outputs for clues about why a test is intermittently failing. Look for patterns or conditions that are present when the test fails.
- Check for external dependencies: Identify if the test depends on external systems or data and verify their stability and availability. Flakiness can often be traced back to these external factors.
- Evaluate timing and synchronization: Analyze whether the test assumes specific timing for certain operations. Introducing flexible wait conditions or timeouts may help stabilize the test.
- Compare environments: Run the test in different environments to see if the failures are environment-specific. This can help pinpoint environmental factors contributing to flakiness.
How to prevent flaky tests

Preventing flaky tests requires a proactive approach to test design and implementation, focusing on creating robust, reliable, and predictable tests. Here are several strategies to help prevent writing flaky tests:
Isolate tests
Ensure each test is isolated and does not depend on other tests’ output or side effects. Tests should be able to run independently and in any order without affecting each other’s outcomes.
Make tests hermetic
Ensure that tests are self-contained and isolated from external influences, dependencies, and environmental variations. A hermetic test should produce consistent and reproducible results and have a deterministic outcome regardless of the external factors or conditions in which it runs. The term “hermetic” is derived from the word “hermetically sealed,” emphasizing the idea of isolation and independence.
Avoid hardcoded timeouts
Hardcoded timeouts can lead to flakiness, especially in environments where execution speed might vary. Use dynamic waits, such as waiting for specific conditions to be met rather than a fixed period where possible.
Ensure test environment stability
Maintain consistency across test environments to minimize the risk of tests passing in one environment but failing in another. Use containerization or virtualization tools to replicate identical test environments.
Employ deterministic inputs
Practice using consistent and predictable input values for tests. Deterministic inputs ensure that the same set of inputs produces the same result every time the test is executed. By avoiding randomness or variability in test inputs, you create a more stable testing environment, reducing the likelihood of flakiness.
Employing deterministic inputs aims for stability by ensuring that specific, known inputs consistently produce the same results.
Leverage property-based testing
Generate tests based on properties or characteristics that the system should have. Instead of specifying specific input values, define general properties that the system must satisfy so that the testing framework generates a variety of inputs to check those properties.
Property-based testing aims for thorough exploration by generating a diverse set of inputs based on defined properties, which may include a range of values.
In practice, combining these approaches can enhance your overall testing strategy. Employing deterministic inputs can address specific scenarios where stability is crucial, while property-based testing can help uncover unexpected issues and ensure robustness across a wider range of input variations.
Handle concurrency carefully
When testing concurrent processes, ensure your tests are designed to handle race conditions and other concurrency issues safely. This might involve using synchronization mechanisms or avoiding shared states between concurrent tests.
Incorporate cleanup and setup routines
Implement thorough setup and teardown routines for your tests to ensure a consistent starting state and cleanup after tests. This helps prevent state leakage between tests.
Utilize retries judiciously
While automatically retrying failed tests can mask the presence of flaky tests, judicious use of retries can help differentiate between transient environmental issues and genuine flakiness. Use retries as a diagnostic tool rather than a solution to flakiness.
Practice continuous monitoring and refactoring
Review and refactor your tests regularly. Look for flaky behaviors and address them promptly. Continuous monitoring helps catch flakiness early before it becomes a significant issue.
Leverage flakiness detection tools
Use tools and plugins specifically designed to detect and manage flaky tests. Many continuous integration platforms offer features to help identify flaky tests by analyzing patterns of test failures over time.
Educate and cultivate awareness
Foster a culture of awareness around the impact of flaky tests and the importance of writing reliable tests. Educating developers and testers on best practices for test stability can lead to writing tests more conscientiously.
By implementing these strategies, teams can significantly reduce the likelihood of introducing flaky tests into their test suites, leading to more reliable, efficient, and meaningful testing processes.
How to prioritize and manage the refactoring process

Prioritizing and managing the refactoring process involves a systematic and strategic approach to improving the reliability and stability of automated tests.
- Assess impact and frequency: Prioritize fixing tests based on their impact on the development process and how frequently they exhibit flakiness. High-impact, frequently flaky tests should be addressed first.
- Categorize flakiness: If possible, group flaky tests by their root causes. Tackling them by category can be more efficient, as similar strategies may apply to multiple tests.
- Monitor and measure: Track which tests are flaky and how often they fail. This data can help prioritize fixing efforts and measure the effectiveness of your strategies over time.
- Allocate dedicated time: Set aside dedicated time for addressing flakiness issues. Regularly scheduled sessions for tackling flaky tests can prevent them from being deprioritized against feature development.
- Incorporate flakiness fixes into sprints: For teams using agile methodologies, include flakiness fixes in your sprint planning. Treating these issues as first-class citizens ensures they receive the necessary attention.
- Encourage collective ownership: Make flakiness a shared concern among your development team and testing team. Encouraging collective ownership helps ensure that insights and solutions can come across the team.
- Document and share learnings: Document the causes of flakiness and the strategies to address them. Sharing these learnings can help prevent similar issues and speed up fixing.
Prioritizing and managing the refactoring process serves as a higher-level guideline for organizing and directing efforts to improve the reliability of automated tests, including the following specific strategies.
Actionable strategies to fix flaky tests

Fixing flaky tests and efficiently managing the process requires a strategic approach to identify the root causes and prioritize remediation efforts effectively. Here are strategies to address both aspects:
| Actionable tip/strategy | Details |
| Isolate the cause | Conduct a binary search by selectively running subsets of tests to pinpoint the specific test or environment conditions causing flakiness. Gradually narrow down the scope until the problematic component is identified. |
| Analyze test logs and outputs | Implement detailed logging within tests to capture key steps, inputs, and outputs. Regularly review logs to identify patterns in failures, and use the information to isolate and address specific issues. |
| Disable and mark the test as flaky/requiring refactoring | Mock or stub external services and dependencies during tests to minimize reliance on live external systems. Isolate tests from the variability of external components to achieve a more predictable and stable testing environment. |
| Adjust timing and waits | Fine-tune wait conditions by using explicit waits based on specific conditions rather than relying on fixed time intervals. Implement dynamic waiting strategies to synchronize with the application’s state changes. |
| Ensure a clean test environment | Set up a pre-test environment configuration step that guarantees a consistent and clean state before each test. This may involve database resets, cache clearing, or other actions to ensure a reliable starting point. |
| Refactor test for determinism | Remove non-deterministic elements, such as random data or dependencies on external states, from tests. Ensure that tests are set up and maintain the required state, promoting consistency in test execution. |
| Address concurrency issues | Identify shared resources or critical sections causing contention among concurrent tests. Implement locking mechanisms or other concurrency control strategies to prevent interference and maintain test isolation. |
| Leverage retries for diagnosis | While not a solution, strategically using retries can help determine whether a failure is sporadic or consistently reproducible under certain conditions. |
Tools and frameworks to help identify and manage flaky tests

Several tools and frameworks have been developed to help identify and manage flaky tests, offering a range of functionalities from detection to analysis and mitigation. Here’s an overview of tools available for various programming languages and testing environments:
1. Test retrying plugins and frameworks
- Flaky Test Handler (for JUnit): This tool is a plugin for JUnit that automatically retries failed tests to distinguish between flaky and consistently failing tests.
- Pytest-rerun failures (for Python): The Pytest plugin that reruns failed tests to identify flakiness.
- TestNG (for Java): Offers built-in support for rerunning failed tests, which can help identify flaky tests.
2. Continuous integration tools with flaky test management
- Jenkins: Jenkins has plugins like the “Flaky Test Handler” plugin, which can help identify and manage flaky tests as part of the CI pipeline.
- GitLab CI/CD: Provides insights and analytics that can help identify patterns of flakiness across multiple test runs. Explore how you can take advantage of GitLab CI/CD and the TestRail CLI with this video: How to integrate TestRail with GitLab CI/CD
- Buildkite: Offers test analytics and allows for automatic retrying of flaky tests with detailed test reports.
3. Dedicated flakiness detection and analysis tools
- Quarantine (various languages): Some CI systems offer or can be configured with a “quarantine” or “exclusion” feature to isolate flaky tests from the main test suite until they can be fixed.
4. Test environment management
- Kubernetes: While not explicitly designed for flaky test detection, containerization tools like Docker and orchestration platforms like Kubernetes can help ensure consistency across test environments, reducing environmental causes of flakiness.
5. Mocking and virtualization tools
- WireMock (for JVM): This tool allows the mocking of HTTP services, which can help isolate tests from external dependencies that might cause flakiness.
- Mockito (for Java): This tool is a mocking framework ensuring unit tests focus on the code being tested, not external dependencies.
- Sinon.js (for JavaScript): This library provides standalone test spies, stubs, and mocks for JavaScript, helping to reduce flakiness in unit tests.
6. Analysis and monitoring tools
- Splunk or ELK Stack: While primarily log analysis tools, Splunk and the Elasticsearch, Logstash, and Kibana (ELK) Stack can monitor and analyze test logs to identify patterns that may indicate flaky tests.
- Prometheus and Grafana: These tools can monitor and visualize metrics, including test execution times and success rates, to help identify flaky tests.
- TestRail: TestRail offers a command-line interface (CLI) that allows you to aggregate and report test automation results efficiently. The TestRail CLI provides a way to integrate automated test results into TestRail, enabling teams to maintain a centralized repository of test results for comprehensive reporting and analysis.

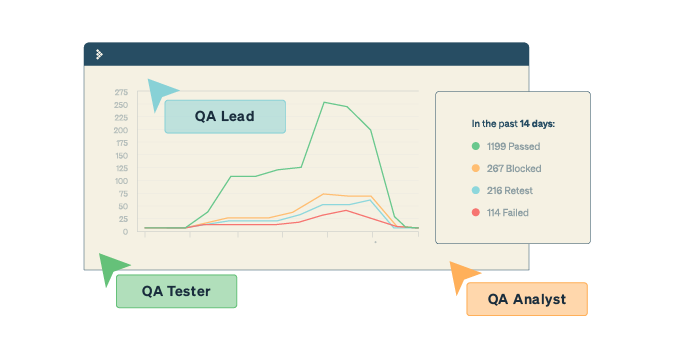
Image: The TestRail CLI allows you to aggregate both your manual and automated testing efforts on reports that give you test coverage insights, track test automation progress and allow you to report a bug directly from the automated test result to an issue tracker of your choosing.
7. Code analysis tools
- SonarQube offers static code analysis, which can help identify potential flaws in the code, such as reliance on unordered collections or improper handling of concurrency.
How a test management tool can help tie it all together
While a test management tool like TestRail doesn’t directly fix flaky tests, it offers features that facilitate the identification, management, and prevention of flakiness in the testing process.
TestRail is a centralized platform for test management, providing visibility into test execution history, allowing for customization of test statuses, supporting documentation, and promoting collaboration. Here’s how TestRail can help:
| Helpful features for identifying flaky tests | Description |
| Test case versioning | TestRail maintains a comprehensive history of test executions. By reviewing past test runs, teams can identify patterns of flakiness and pinpoint tests that consistently exhibit instability. |
| Custom test status | Customize test statuses to include a category for flaky tests. This allows teams to explicitly mark tests that are known to be flaky, providing visibility to both testers and developers. |
| Test result attachments | Attach screenshots, logs, or additional details to test results. This can be valuable in capturing evidence and context when a test fails intermittently, aiding in the identification of flakiness. |
| Helpful features for managing flaky tests | Description |
| Test case organization | This feature allows users to categorize test cases based on priority, criticality, or other relevant factors. This helps in focusing efforts on managing and refactoring tests that have a higher impact. |
| Test configurations | This allows you to run the same test against different configurations, making it easier to identify whether flakiness is specific to certain environments or conditions. |
| Helpful features for preventing flaky tests | Description |
| Requirements linkage | Link test cases to specific requirements to develop more stable tests that accurately reflect the expected behavior. |
| Test case documentation | Makes it easy for your team to clearly define preconditions, steps, and expected results, reducing ambiguity and contributing to the creation of more deterministic tests. |
| Collaboration and reporting | Leverage TestRail’s collaboration features to facilitate communication between testers and developers. Generate reports and share insights on test reliability, making it easier for teams to collaborate on addressing flaky tests. |
| Integration with CI/CD tools | Integrate TestRail with continuous integration and delivery (CI/CD) tools. This ensures that test runs are triggered automatically, helping teams catch and address flaky tests early in the development pipeline. |
| Test case maintenance | Regularly update and maintain test cases easily in TestRail. As your software evolves, outdated test cases may contribute to flakiness. Keeping test cases current ensures they accurately reflect the application’s behavior. |
Bottom line
A steadfast stance against flakiness is non-negotiable for high-quality software development.
Flaky tests challenge the reliability of our automated testing efforts. Still, with a systematic approach to identifying, understanding, preventing, and fixing them, we can enhance the stability and predictability of our test suites.
Embrace these strategies to minimize flakiness and maximize confidence in your continuous integration and deployment processes.
If you want to learn how to flag flaky tests with TestRail, using a custom field, check out our free TestRail Academy Test Automation course!
I am a woman who is deeply passionate about coding and software testing. With every line of code I write and every test I conduct, I am driven by a desire to create reliable and innovative software solutions. With over 8 years of experience as a Staff Software Engineer in Test, I am deeply passionate about the world of software testing and quality assurance. My expertise spans a wide spectrum of testing domains, including UI, API, load testing, integration testing, end-to-end testing, and performance testing with architecting testing solutions for complex problems. What truly fuels my passion is the thrill of uncovering intricate bugs that challenge the robustness of applications.”